Your App Deserves Better Than 'Whatever The LLM Shits Out': The Pre-Planning Revolution

The unpredictability of AI coding assistants stems from a fundamental communication problem that few are discussing: the low information compactness of natural language. In our previous examination of the "gaslighting" nature of these tools, we explored how their inconsistent performance creates a costly uncertainty tax for developers. Today, I want to propose that this inconsistency isn't random—it's the predictable result of attempting to convey dense technical specifications through the loose, context-dependent medium of English.
Correcting the "Vibe Coding" Misconception
Before diving deeper, I need to address a dangerous misconception that's taken hold in developer communities. The emerging concept of "vibe coding"—where developers essentially accept whatever an LLM generates as long as it works—represents a fundamental misunderstanding of effective AI-assisted development.
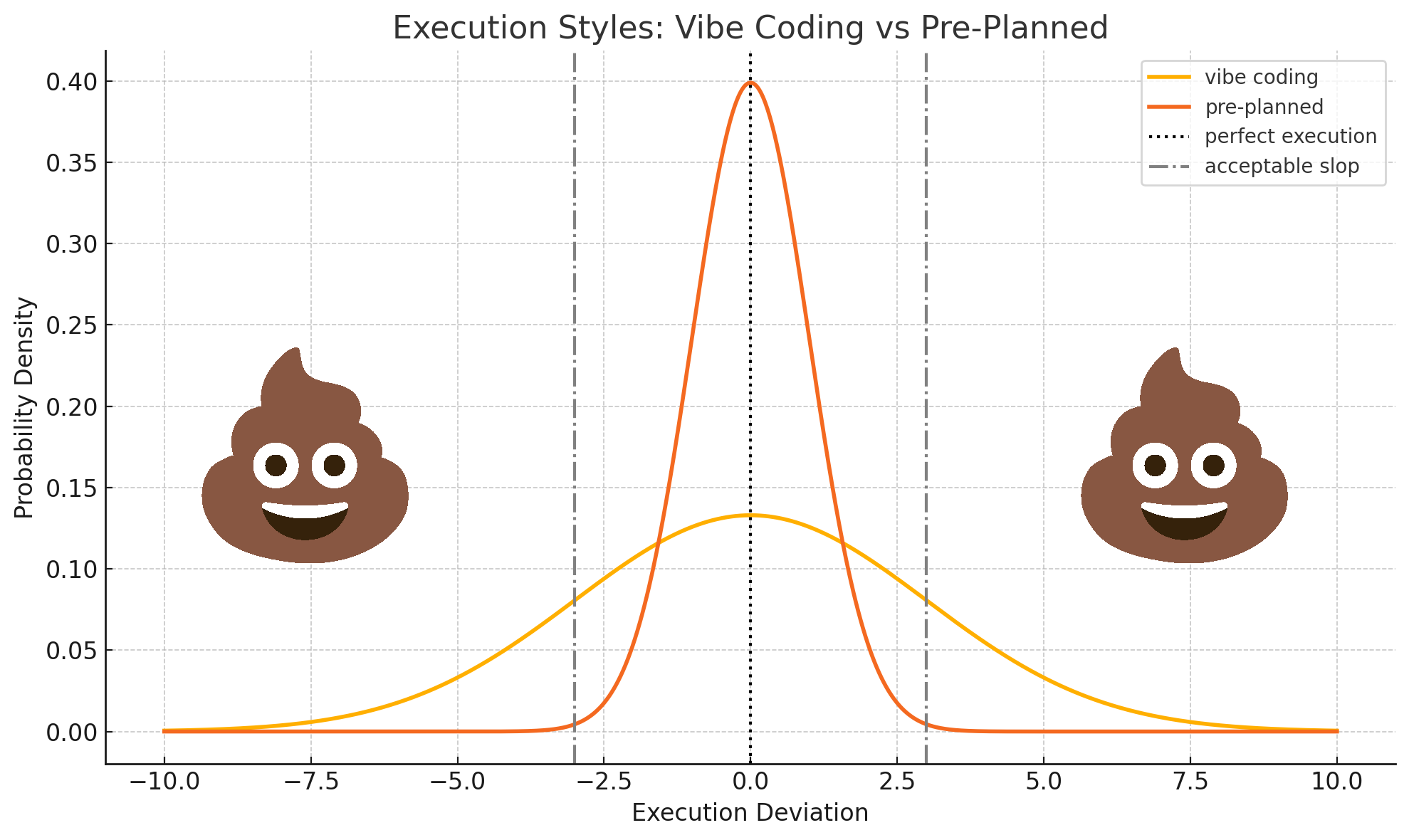
Looking at the graph comparing execution styles, we see something crucial: pre-planned approaches (the red line) produce a narrow, tall distribution centered close to perfect execution. This means pre-planning leads to more consistent and typically better outcomes. The so-called "vibe coding" approach (yellow line) produces a wide, flat distribution—meaning highly unpredictable results that frequently fall outside acceptable parameters.
This directly contradicts the current zeitgeist, which often portrays "vibe coding" as the path to productivity. The data shows precisely the opposite: pre-planning with detailed boundary specifications drastically reduces variance and improves outcomes. The width of the distribution isn't something to embrace—it's something to mitigate through careful specification.
The Hidden Information Gap
Every spec discussion between human developers is filled with unspoken context. When a senior developer tells a junior to "add validation to that form," the instruction carries with it volumes of unstated information: company coding standards, previous validation patterns used in the project, industry best practices, security considerations relevant to their domain, and often implicit performance requirements. None of this is actually spoken—it lives in the shared context between professionals.
The graph comparing "vibe coding" versus "pre-planned" approaches provides clear evidence against the current "just vibe with it" trend. Pre-planned coding—where detailed specs are meticulously crafted upfront with emphasis on system boundaries—produces a tight, consistent cluster of outcomes (the tall, narrow red curve). This represents lower variance and higher predictability.
Despite what's currently being advocated in some circles, the yellow "vibe coding" distribution shows exactly why the approach is problematic—its wide, flat distribution indicates high unpredictability with many outcomes falling outside acceptable parameters (the vertical dash-dot lines). This isn't because planning is unnecessary; it's because without proper boundary specifications, LLMs are forced to fill in massive context gaps with their generalized training data.
The Dual Role of Pre-Planning
This perspective reveals an interesting tension in the pre-planned approach. Traditional software specifications attempt to formalize all of this hidden context—to make explicit what would otherwise remain implicit. In theory, this should produce more consistent results. In practice, however, the pre-planned approach often fails to capture crucial context, not because developers are careless, but because much of this context is so deeply internalized that we don't even recognize it as "context" that needs stating.
A senior developer writing a detailed spec will naturally focus on articulating the non-obvious parts of the implementation while omitting the "obvious" elements—not realizing that "obvious" is itself a context-dependent concept. What's obvious to one team with their specific technology stack and history is completely non-obvious to an LLM with a generalized understanding of code.
The true value of pre-planning isn't in its comprehensiveness—it's in its ability to transform some of the team's implicit context into explicit instructions. The challenge is that we can never completely externalize all relevant context because we're rarely consciously aware of its full extent.
The Boundary-Focused Pre-Planning Model
What emerges is a new model for LLM-assisted development: the vast majority of time should be spent on detailed pre-planning that specifically bridges the gap between the LLM's world context and your application's unique context. This isn't traditional software specification—it's a new form of documentation focused explicitly on what makes your application different from the thousands of similar applications the model has "seen" during training.
The most critical elements of this pre-planning process are system boundaries—the interfaces, interactions, and specific behaviors where different components of your system meet and communicate. These boundaries are what make your application unique:
- API Contracts: The precise shape, behavior, error handling, and edge cases of your API endpoints
- Component Interfaces: The exact props, state management, and lifecycle behaviors of your UI components
- Data Flow Junctions: How information travels between systems, including transformations and validations
- State Transitions: The specific rules governing how your application moves between states
- Integration Points: How your code interacts with external systems, libraries, and services
While an LLM might reasonably infer typical implementation patterns for a standard REST API or React component, it cannot possibly know the specific boundary conditions and interfaces unique to your system. These boundaries constitute the "application fingerprint" that separates your implementation from the generic world context.
Information Density: Human vs. Machine Communication
The fundamental issue is that English and other natural languages evolved for human-to-human communication, where shared context creates extraordinary information density despite linguistic imprecision. A developer who tells a colleague "this needs to be RESTful" is transmitting a rich technical specification in five words because both parties share years of accumulated context about what constitutes proper REST implementation.
When we communicate with LLMs, this information compression fails spectacularly. The model lacks:
- Project History Context: The accumulated decisions, trade-offs, and conventions specific to your codebase.
- Tacit Professional Knowledge: The unwritten rules and patterns that experienced developers in your field simply "know."
- Intention Context: The underlying "why" behind a feature request that often shapes implementation details.
- Cultural Context: The organizational values that subtly influence technical decisions (e.g., "we prefer readable code over clever optimizations").
- Temporal Context: Awareness of which libraries, approaches, or patterns are currently favored in your development ecosystem.
This context gap creates a communication chasm that no prompt, however carefully crafted, can fully bridge. Every word you don't explicitly specify becomes a vector for variance.
The World Context Advantage
And yet, despite these contextual limitations, LLMs have proven remarkably useful for coding tasks. This seeming contradiction can be explained by understanding what these models do have: a form of "world context" representing the shared practices, patterns, and knowledge common to developers globally.
Through their training on vast corpora of code and technical writing, LLMs have absorbed something akin to the collective wisdom of the programming community. They understand common design patterns, typical error handling approaches, standard documentation formats, and prevailing architectural styles. This world context means they're not starting from zero—they begin with a generalized approximation of developer knowledge.
The goal of effective LLM coding, then, is to refine this general world context into your specific use case context. You're essentially navigating from "how most developers might implement this" to "how our team implements this given our unique constraints and preferences." The narrower distribution of vibe coding represents this progressive refinement process—moving from general practice to specific implementation through iterative feedback.
Vibe Coding: Iterative Context Transmission
This is where "vibe coding"—the iterative, conversational approach to LLM programming—proves its worth. It's not about embracing randomness; it's about acknowledging that context transmission between humans and machines requires a fundamentally different approach than our existing specification methodologies.
The technique works through progressive context enrichment:
- Initial Skeleton: Your first prompt establishes basic intent with minimal detail.
- Contextual Layering: Each subsequent interaction adds another layer of the implicit context that was missing from your initial description.
- Feedback Compression: When you reject an output and explain why, you're not just fixing an error—you're transmitting critical context that was absent from your original spec.
- Boundary Exploration: Seeing how the model fails reveals the gaps in your transmitted context more effectively than trying to proactively identify them.
- Implicit Standards Transfer: As you approve certain approaches and reject others, you're building a local, session-specific knowledge base of your standards and preferences.
This iterative approach isn't inefficient—it's the most efficient possible method for transferring the vast implicit context that exists in your mind but not in your words.
The Language Information Density Problem
This perspective explains why the current trend toward "vibe coding" is fundamentally misguided. The formal specification language we've developed for software engineering is optimized for human-to-human communication where massive shared context exists. When communicating with LLMs, failing to provide detailed boundary specifications inevitably results in the wide, unpredictable yellow distribution we see in the graph—with many outcomes falling outside acceptable parameters.
Consider these common spec phrases and the vast context they encapsulate:
- "Make it scalable" (Implies specific architectural patterns, avoidance of certain algorithms, infrastructure assumptions, and load characteristics—none explicitly stated)
- "Follow best practices" (Contains an entire professional literature's worth of evolving standards specific to language, framework, and problem domain)
- "Keep it maintainable" (Encompasses company-specific code organization conventions, documentation standards, and test coverage expectations)
These phrases work between humans because we share context. Between human and AI, they're information voids waiting to be filled by the model's training distribution—a recipe for the wide variance shown in the yellow "vibe coding" distribution.
The narrow, tall red curve of pre-planned implementation represents the proper approach—not accepting whatever the model generates, but carefully constraining the problem space through detailed boundary specifications to ensure outcomes consistently fall within acceptable parameters.
Practical Implementation: Context-Aware Prompting
Understanding this information density problem leads to a more effective approach to AI coding assistance:
- Explicit Context Dumping: Start by articulating the typically unspoken context. "This is for our e-commerce platform written in TypeScript with Next.js. We follow a functional programming style and prioritize test coverage over development speed."
- Example-Driven Communication: Examples transmit implicit context far more effectively than abstract descriptions. "The error handling should look like this..." conveys volumes of unspoken standards.
- Progressive Revelation: Accept that you cannot transfer all context upfront. Plan for multiple iterations where each exchange reveals more of what was implicitly assumed but not stated.
- Context Boundary Testing: Deliberately test the model's understanding of your unstated assumptions. "How would you handle network timeouts here?" quickly reveals if critical reliability context was successfully transmitted.
- Reference Point Anchoring: Establish shared reference points early. "This should follow the same patterns as the authentication module I showed you earlier" leverages previously transmitted context.
The goal isn't to create perfect prompts—it's to systematically bridge the context gap that exists between your mind and the model's understanding.
English vs. Code: The Fundamental Mismatch
The core issue is that programming languages and natural languages operate at vastly different information densities, with opposite assumptions about context:
- Programming Languages: High information density, explicit context. Every variable must be declared, every function signature defined, every dependency imported. Nothing is assumed.
- Natural Languages: Low information density, implicit context. Most meaning exists between the lines, in shared cultural knowledge, professional background, and conversational history. Everything is assumed.
When we try to bridge these worlds through AI coding assistants, we're attempting to translate from a low-density, high-context medium (English) to a high-density, no-context medium (code). The information must come from somewhere—and what isn't explicitly provided will be implicitly filled in by the model's training distribution.
The graph illustrates this principle perfectly. The wide distribution of pre-planned approaches represents the massive variance in how missing context can be filled. The narrower distribution of vibe coding represents the progressive elimination of this variance through iterative context transmission.
From World Context to Local Context
The most effective prompting strategy recognizes the journey from world context to local context. LLMs don't know your specific codebase, but they do understand the global patterns of how similar codebases are typically structured. Your task is to guide the model from this general understanding to your specific implementation.
Pre-planning is not about accepting a wide variance of outcomes, as some "vibe coding" proponents suggest. On the contrary—as the graph clearly shows—proper pre-planning with boundary specification (red line) produces remarkably consistent outcomes within acceptable parameters. This approach works best when:
- You invest substantial upfront time in boundary specification before any code is written
- You focus on interfaces rather than implementations
- You explicitly document system behaviors at integration points
- You provide concrete examples of how similar patterns are implemented elsewhere in your codebase
The narrow, tall distribution curve of pre-planned approaches in the graph represents success—it shows how proper boundary specification drastically reduces variance. The unacceptably wide "vibe coding" distribution (yellow line) isn't something to celebrate or "embrace"—it represents the failure to properly constrain the problem space through adequate specification.
Boundaries as the Essential Context Bridge
What the data increasingly shows is that effective LLM-assisted coding requires a fundamental shift in how we approach specification. Rather than attempting to document everything, we need a boundary-focused planning model that concentrates on the unique aspects of our application—specifically how different components interact.
This means:
- Less implementation detail: The LLM already understands standard implementation patterns
- More interface specification: Precise documentation of inputs, outputs, and error conditions
- Explicit state management: Clear articulation of how application state flows through boundaries
- Behavior at edges: Specific handling of edge cases at component interfaces
- Example-driven boundary definition: Concrete examples of how existing boundaries work in your system
By focusing pre-planning efforts specifically on system boundaries—the truly unique fingerprint of your application—you maximize the value of upfront specification while minimizing the inevitable context gaps that lead to implementation variance.
Conclusion: Towards Context-Aware Coding Assistance
AI coding assistants aren't failing because they're not smart enough—they're failing because we're communicating with them using tools designed for a completely different type of information exchange. Human language evolved specifically to leverage vast shared context between similar minds. When we use it to communicate with fundamentally different systems, the context gap becomes the dominant source of unpredictability.
The value proposition of LLMs is not that they understand your specific context—it's that they understand the shared world context of software development. They know what "most developers would do" in a given situation. The data is clear: your job is not to "vibe" with whatever the model generates, but to guide it through comprehensive boundary-focused pre-planning that explicitly documents how your system is unique.
The graph conclusively demonstrates that the current trend of "vibe coding"—where developers accept whatever an LLM generates as long as it works—leads to highly unpredictable outcomes that frequently fall outside acceptable parameters. In contrast, proper pre-planning with detailed boundary specifications produces remarkably consistent results that stay within acceptable bounds.
The most productive approach to LLM-assisted development follows this pattern:
- Extensive Boundary Planning: Invest substantial time before coding in documenting system boundaries, interfaces, and component interactions—the unique fingerprint of your application
- World Context Leveraging: Allow the LLM to handle standard implementation patterns without excessive specification
- Parameter Constraint: Clearly define acceptable bounds for implementation, reducing the variance in outcomes
This approach acknowledges that LLMs excel at generating code within established patterns but struggle with the unique aspects of your system. By focusing your specification efforts specifically on boundaries—the interfaces and interactions between components—you achieve the narrow, consistent distribution shown in the red curve.
The future of effective AI coding assistance lies not in surrendering to the wide variance of "whatever the LLM generates," but in developing communication protocols and specification techniques specifically designed for human-AI collaboration—tools that help extract and formalize the boundary-specific context that separates your application from the generic world context the model already understands.
The developers who master this boundary-focused specification—who learn to explicitly document the interfaces and interactions that make their system unique—will extract dramatically more value from AI assistants than those who adopt the dangerously unpredictable "vibe coding" approach currently being promoted.
In the end, effective LLM-assisted development isn't about accepting whatever the model generates. It's about providing clear boundary constraints that narrow the probability distribution to a tight band of acceptable outcomes.