Stop Calling It an ‘Agent’: Why the Term Has Run Its Course

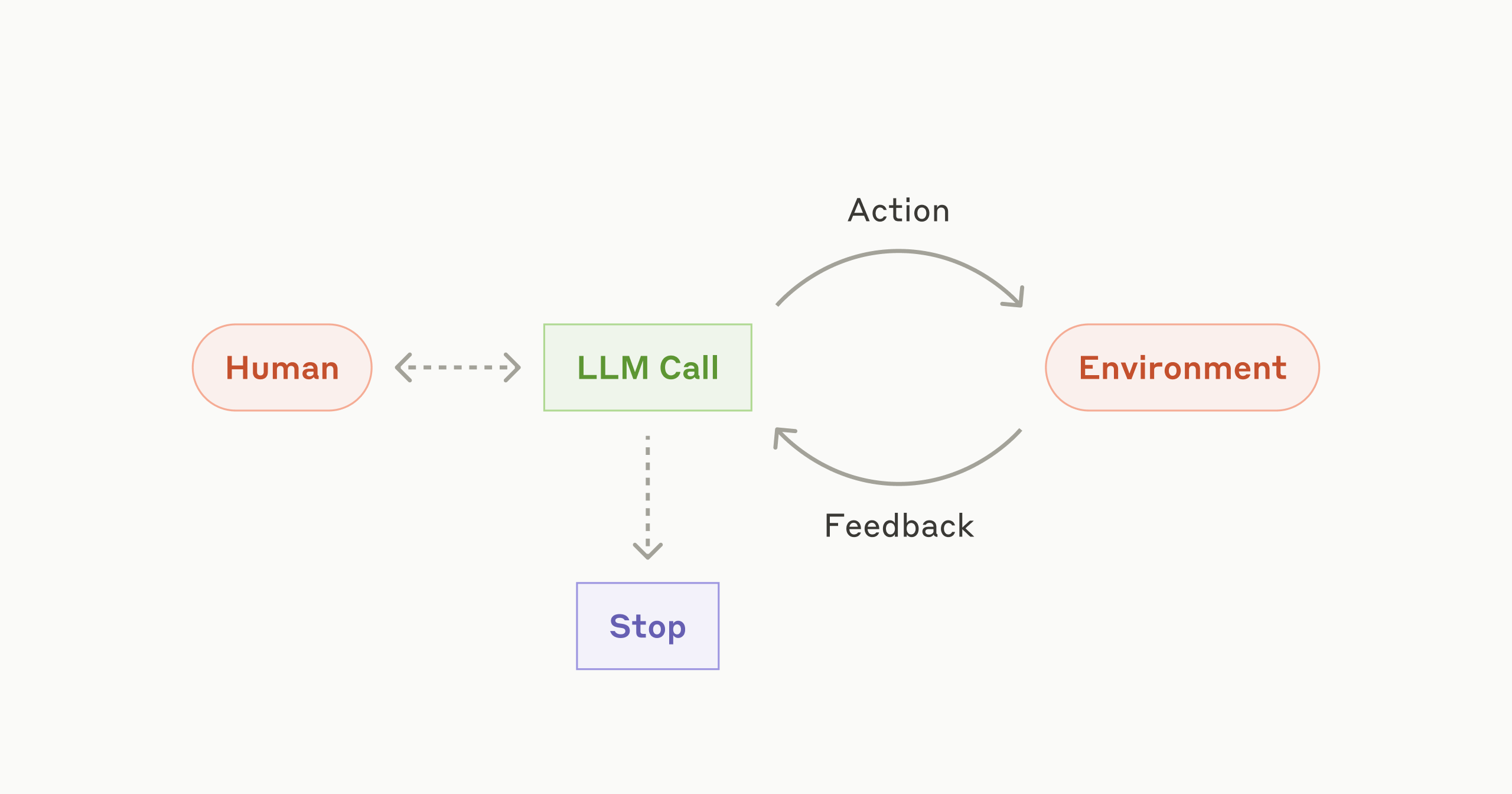
Anthropic's take on agents.
Over the last year, everyone in AI seems to be talking about “agents,” a buzzword that promises everything from open-ended autonomy to flexible decision-making across complex tasks. But when you look under the hood of these “agents,” you often find a standard codebase with an LLM integrated for text generation. In many cases, calling them “agents” obscures crucial details—especially around which parts of the system are deterministic and which parts are non-deterministic. This post argues that “agent” is not a helpful category and that Anthropic’s proposed boundary between “workflows” and “agents” doesn’t meaningfully clarify how these systems actually operate.
Below, we’ll explore four core objections to the term “agent,” then directly address Anthropic’s claim that “workflows” and “agents” represent distinct architectural concepts. Ultimately, we’ll show that so-called “agents” are just more complex LLM workflows, not a fundamentally separate category of AI design.
1. “Agent” Masks the Underlying Workflow
The first problem with the term “agent” is how it flattens all the behind-the-scenes orchestration into a single mystical entity. In reality, these systems revolve around carefully scripted steps:
- Scripted Logic – Developers write functions, conditionals, loops, and data-handling code to orchestrate tasks.
- LLM Calls – Text generation or “reasoning” is farmed out to an LLM at specific points in the workflow.
- Tool Usage – The LLM might access APIs or databases, but only as allowed by code that developers predefine.
For example, a “Travel Planning Agent” might look autonomous from the outside, but behind the scenes, the orchestrator code systematically calls the LLM for each sub-task—search flights, book a hotel, propose an itinerary—and funnels the model’s outputs back into a structured pipeline. Calling it an “agent” suggests a self-contained system that “just decides” its own path, when in fact the deterministic code controls the flow at every step, merely invoking the LLM for text-based input or output. A more transparent term—like “multi-step LLM workflow”—better captures this relationship.
2. “Agent” Hides the Real Boundary Between Deterministic and Non-Deterministic Code
One of the biggest misconceptions introduced by the “agent” label is that it obscures which parts of the system are truly up for grabs (non-deterministic) and which parts have been rigidly scripted (deterministic). In Anthropic’s article, they carve out “agents” as systems where LLMs “dynamically direct their own processes and tool usage,” while “workflows” are more rigidly defined. However, even in Anthropic’s own examples (like a coding assistant or a customer-support bot), the separation between a supposed “agent” and a standard multi-step workflow often amounts to a question of how frequently the LLM is polled and how many calls it’s allowed to make. The actual boundary—the line where the code’s path can diverge based on the model’s output—still depends on deterministic scaffolding that developers put in place.
The Illusion of Fully Dynamic Control
Take Anthropic’s discussion of “agents” that can call different tools and decide how to navigate subtasks on their own. They position these systems as though the LLM spontaneously chooses from an open-ended library of actions. In reality, each “tool” is carefully defined and documented so that the LLM can only invoke a constrained set of functions, each with specific arguments and expected behaviors. The code that controls these tools—managing parameters, error handling, or timeouts—is almost always 100% deterministic. Thus, even if the LLM is “deciding” which tool to call, it does so under the watchful guidance of a developer-crafted orchestrator that strictly enforces what is possible. Calling this arrangement an “agent” glosses over how few degrees of freedom the LLM truly has.
The Central Role of Orchestration
Anthropic’s own “workflow” examples—like “prompt chaining,” “routing,” and “parallelization”—underscore that every step is spelled out in code or in a node-based UI. The difference they propose for “agents” is that the LLM can “maintain control” of the sequence in which tools are called. But this is still orchestrated by a predetermined loop that repeatedly calls the LLM until a stopping condition (which is also developer-defined) is met. Even if the LLM proposes a plan or spontaneously decides, “Let’s now call Tool X,” there’s always a chunk of code waiting to parse that text and handle it. If the LLM’s plan doesn’t match a valid tool signature, or if it asks for something out of scope, the orchestrator code typically blocks or redirects it. Far from being non-deterministic, the system’s high-level flow is locked in from the start.
Overlooking the Deterministic Checks and Balances
Anthropic’s “autonomous agent” archetype provides a good illustration of how “dynamic” these systems really are. They describe a scenario in which the LLM iteratively refines its approach, calling tools and re-checking its results. But the minute the system hits a snag—like an unrecognized tool name, an API error, or an exceeded iteration limit—hard-coded rules in the orchestrator define the fallback plan (e.g., reprompt the model, issue an error, or halt the loop). If the LLM tries to push beyond those boundaries, it’s shut down by logic that’s entirely deterministic. This interplay is crucial: the system only appears fluid if the user never triggers these guardrails. In practice, all “agentic” demonstrations rely on the orchestrator working flawlessly behind the scenes, which contradicts the idea that the LLM is truly “directing its own processes.”
A More Transparent Way to Discuss System Design
By calling everything “agentic,” Anthropic’s article does not emphasize the deeper question: Which aspects of the system are truly emergent or probabilistic, and which aspects are orchestrated by code that must be correct 100% of the time? The term “workflow” at least hints at an assembly of discrete steps. But “agents,” as described by Anthropic, often just take “workflow” patterns and inject more LLM calls—or allow the LLM to pick which subroutine to run next. Rather than clarifying where the system’s unpredictability actually lies, the “agent” framing conflates the LLM’s text-generation freedom with code-level decisions that developers have already nailed down. A clearer vocabulary—like “a multi-step LLM pipeline with dynamic subroutine selection”—forces us to be explicit about which steps are scripted and which steps rely on the LLM’s non-deterministic outputs. That shift in focus is critical for debugging, reliability, and understanding real-world limitations.
Ultimately, Anthropic’s distinction between “workflows” and “agents” sidesteps the determinism question: all such systems rely on a combination of structured control flow plus LLM-driven text generation. The truly meaningful conversation isn’t whether you call the system an “agent” or a “workflow,” but how you delineate the code’s fixed logic from the model’s variable responses. By centering the discussion on that boundary—rather than the label “agent”—we gain a clearer view of the system’s capabilities, its constraints, and where real autonomy (if any) might lie.
3. The “Agent” Boundary Is Arbitrary—and Often Contrived
A central claim in Anthropic’s article is that “agents” differ from standard “workflows” in that they give LLMs more dynamic control over which tools to call and how to accomplish tasks. Yet when you scrutinize the actual mechanisms, the supposed boundary between “agent” and “workflow” is often just a matter of how many times the LLM is polled or how many options the code offers. In other words, the line between “You’re a predefined workflow” and “You’re an agent” is mostly a subjective label rather than a clear-cut technical distinction.
Multiple LLMs vs. Multiple “Agents”
Consider Anthropic’s “orchestrator-workers” or “parallelization” workflows, where you might have separate LLM calls for different subtasks. Does that automatically imply multiple “agents” conversing with each other? Or is it simply a single system orchestrating multiple prompts in sequence or in parallel? Anthropic sometimes frames these as “multi-agent” setups, but the difference from a more basic workflow can be as trivial as duplicating the LLM prompt logic and applying it to multiple data chunks. One developer might say, “I have a single ‘agent’ that branches into sub-routines,” whereas another developer, using almost identical code, might say “I have three separate agents.” Both descriptions are correct from a marketing perspective, but they’re functionally identical in how the system operates.
Shallow vs. Deep Autonomy
Anthropic also invokes the idea that “agents” can “maintain control” over how they accomplish tasks. However, any “control” the LLM appears to have is a direct byproduct of the code that enumerates which tools or subtasks exist. Just because the LLM can choose from a finite tool set doesn’t mean it can spontaneously invent a brand-new function or override crucial safety checks. The logic that halts the process, logs errors, or resets the system after too many failed attempts is still developer-authored. Consequently, labeling one workflow “agentic” and another “not” can boil down to whether the LLM is permitted to call Tool A or Tool B on its own—an arbitrary boundary that reveals more about how code is structured than about genuine autonomy.
One Agent or Many?
The ambiguity is amplified when Anthropic discusses multi-agent systems, where multiple LLM “agents” can “collaborate” on a task. At face value, this sounds significantly different from a single LLM approach—yet in practice, these are often just orchestrations that alternate calls to multiple LLM endpoints, passing text from one model to another. You could just as easily collapse that into a single LLM with multiple role prompts, or break it into five “agents” instead of two. There’s no principled, universal criterion telling you exactly when two LLM prompts constitute two different “agents” versus one more complex prompt or workflow. The dividing lines are entirely developer-imposed.
Arbitrary Definitions Undermine Clarity
Ultimately, Anthropic’s distinction between “agents” and “workflows” can obscure design decisions that truly matter. How do you handle failures? When do you stop iterating? Which data do you log and reuse? These are the real engineering questions—yet by framing them in terms of “agentic vs. non-agentic,” Anthropic implies a categorical difference that often isn’t there. A more precise discussion would sidestep the “agent” label altogether and say: “We allow the LLM to pick from a list of tool APIs in a loop until it either meets a success condition or hits a fail-safe.” That description highlights the actual structure and constraints instead of promoting the illusion that the system gained a distinct identity or additional autonomy merely by toggling how many times it can call a tool.
4. The LLM Does the Heavy Lifting—So Why Call It an “Agent”?
The LLM Does the Heavy Lifting—So Why Call It an “Agent”?
A core issue with Anthropic’s framing is that it suggests these “agents” derive their power from architectural novelty—when, in truth, the real intelligence lies in the large language model (LLM) itself. All the “agentic” scaffolding described in their article largely comes down to how often the system calls the LLM, which tools the LLM is allowed to invoke, and whether code re-prompts the LLM based on intermediate results. If you peel away that scaffolding, the core capability—generating coherent text, reasoning over a context, or producing code—remains the exact same language model. In other words, the “agent” label adds an air of autonomy, but the heavy lifting is still just token generation, powered by the LLM’s extensive training.
Overstating the Impact of Loops and Tool Calls
Anthropic’s examples of multi-step “agentic” patterns, like the “Evaluator-Optimizer” workflow or the “Orchestrator-Workers” model, illustrate how software repeatedly consults the LLM for partial solutions, checks them, and feeds them back. Yes, that can be useful for error correction, iteration, or modularizing tasks—yet none of these steps magically make the system more agentic in the sense of independent intelligence. The LLM remains the star performer, doing everything from summarizing text to writing code. The rest—managing how many times to iterate, which API calls to permit, or when to stop—is code that any developer could write, absent the LLM’s creative potential. Calling it an “agent” can obscure this fact by implying there’s more than an LLM plus a loop at play.
The Illusion of Sophisticated Autonomy
Anthropic positions “agents” as though they possess a special capacity to “maintain control” over their own task flow, or “choose” which tool to use. But the only reason those choices feel autonomous is because the LLM is generating text that describes how it wants to proceed; the code then interprets those instructions and executes them—if they match the developer-defined schema. Even in Anthropic’s “autonomous agent” scenarios, the deciding factor remains the LLM’s textual output, not some extrinsic logic that fosters real volition or decision-making. This means that if you replaced the LLM with a less capable model, all that “agentic” scaffolding would collapse into something far less impressive. Hence, it’s clear the LLM itself is doing the intellectual heavy lifting; the agent label merely dresses it up.
Rebuttal: Anthropic’s “Building Blocks” vs. True Intelligence
Anthropic places emphasis on building blocks like “retrieval,” “tools,” and “memory,” presenting them as if they’re key to creating a higher-order “agent.” Yet each of these enhancements—retrieving documents, calling an API, persisting conversation history—is still reliant on the LLM’s ability to integrate new tokens into its context window. The intelligence behind deciding how to use that retrieved content or how to interpret memory traces is still the model’s language-generation capacity. The scaffolding just ensures the LLM has an interface to external data. This is helpful, but it doesn’t constitute a new category of intelligence that merits the label “agent.” It’s more like giving the LLM an expanded context (e.g., a retrieved snippet) or a domain-specific prompt (e.g., instructions on how to call an API).
A More Honest Description: LLM-Centric Systems
Ultimately, Anthropic’s patterns—prompt chaining, routing, parallelization, orchestrator-workers—rely on the same principle: the LLM is the one “thinking,” while the code is simply directing traffic. The more complex the traffic management, the more likely someone might call it an “agent.” But if the code is simply running repeated queries and hooking into structured prompts, it’s still just an LLM-based system with procedural scaffolding. A more transparent nomenclature might be “LLM-centric architecture” or “multi-step LLM system,” which keeps the spotlight on the model’s capabilities rather than attributing them to a vaguely defined “agent.” By acknowledging that the LLM is fundamentally doing the heavy lifting, we sidestep marketing hype and focus on how to reliably engineer the system around that central intelligence.
Anthropic’s Distinction Between Workflows and Agents
Anthropic proposes a neat distinction:
- Workflows are systems where “LLMs and tools are orchestrated through predefined code paths.”
- Agents are systems where “LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.”
While this framing sounds tidy, it ultimately doesn’t hold up under scrutiny:
- All “Agents” Are Still Orchestrated
Even Anthropic’s so-called agents rely on some piece of code that loops, checks outputs, and decides what to pass to the model next. The difference is that the LLM might choose among a predefined set of tools—or decide how many steps to iterate. But the available tools, the loop conditions, and the high-level structure are still coded by humans. There’s no fundamental line where the system magically transitions from “workflow” to “agent.” It’s a continuum of how often we query the LLM and how flexible the scripts are. - Where Is the Deterministic/Non-Deterministic Boundary?
Anthropic’s articles mention that “agents” maintain control over how they accomplish tasks. However, they rarely clarify which decisions are truly emergent from LLM calls (non-deterministic) vs. which decisions are enforced by code (deterministic). For instance, in their “autonomous agent” example, the model might decide to call a particular tool, but the actual function signature, error handling, and iteration limits are still developer-defined. So is that “agentic control,” or just a more flexible workflow? - “Agentic Systems” vs. “LLM Workflows”
When Anthropic lumps everything into “agentic systems” (with workflows as a subset), they’re mostly rebranding multi-step LLM usage. Their “prompt chaining,” “routing,” “parallelization,” and “orchestrator-workers” patterns are simply standard software design plus an LLM, not a fundamentally different category of AI. Calling them “agents” or “agentic workflows” doesn’t clarify the architecture; it merely adds a layer of marketing language. - Over-Focus on Autonomy at the Expense of Architecture
By distinguishing “agents” from “workflows,” Anthropic emphasizes autonomy—like the idea that “agents plan and operate independently.” But all these examples (customer support, coding tasks) actually show how reliant the system remains on a scripted framework. The real question should be: Which parts are you hardcoding? Which parts do you let the LLM decide? That question cuts across every example and is more illuminating than whether you call it a “workflow” or an “agent.”
In short, Anthropic’s line between workflows and agents appears more philosophical than technical, and it doesn’t offer a clearer lens for system design. The real conversation should focus on how code orchestrates the LLM, how much latitude the model has to choose next steps, and what guardrails are in place—all points that could be discussed just as easily (and more transparently) without calling anything an “agent.”
Conclusion: Let’s Move Beyond “Agents”
Despite Anthropic’s attempt to categorize “agents” as a special, more autonomous breed of LLM-driven software, we still find that every so-called agent is essentially a multi-step LLM workflow with varying degrees of flexibility in how prompts and tools are selected. If the real boundary of interest is how deterministic code orchestrates non-deterministic model calls, the “agent” label adds little beyond marketing flair.
A better path forward is to:
- Highlight Deterministic vs. Non-Deterministic Boundaries: Spell out which parts of the system are code-driven vs. LLM-driven.
- Openly Discuss Orchestration: Show how you chain prompts, manage error cases, and decide when to call which tool.
- Avoid Artificial Categories: Rather than dividing “workflows” and “agents,” recognize that everything lies on a continuum of code orchestration and LLM usage.
Ultimately, retiring the “agent” term frees us to have more precise conversations about how these systems work—and helps us avoid hype that overshadows the very real challenges and advancements in LLM-based software. It’s time to call these structures what they really are: LLM workflows with carefully designed control logic, not mystical digital beings that act on their own.